id:anatooのブログ
2024年1月8日
Webパフォーマンス2023年10月31日
雑記2023年1月18日
Wasm2022年2月16日
Webパフォーマンス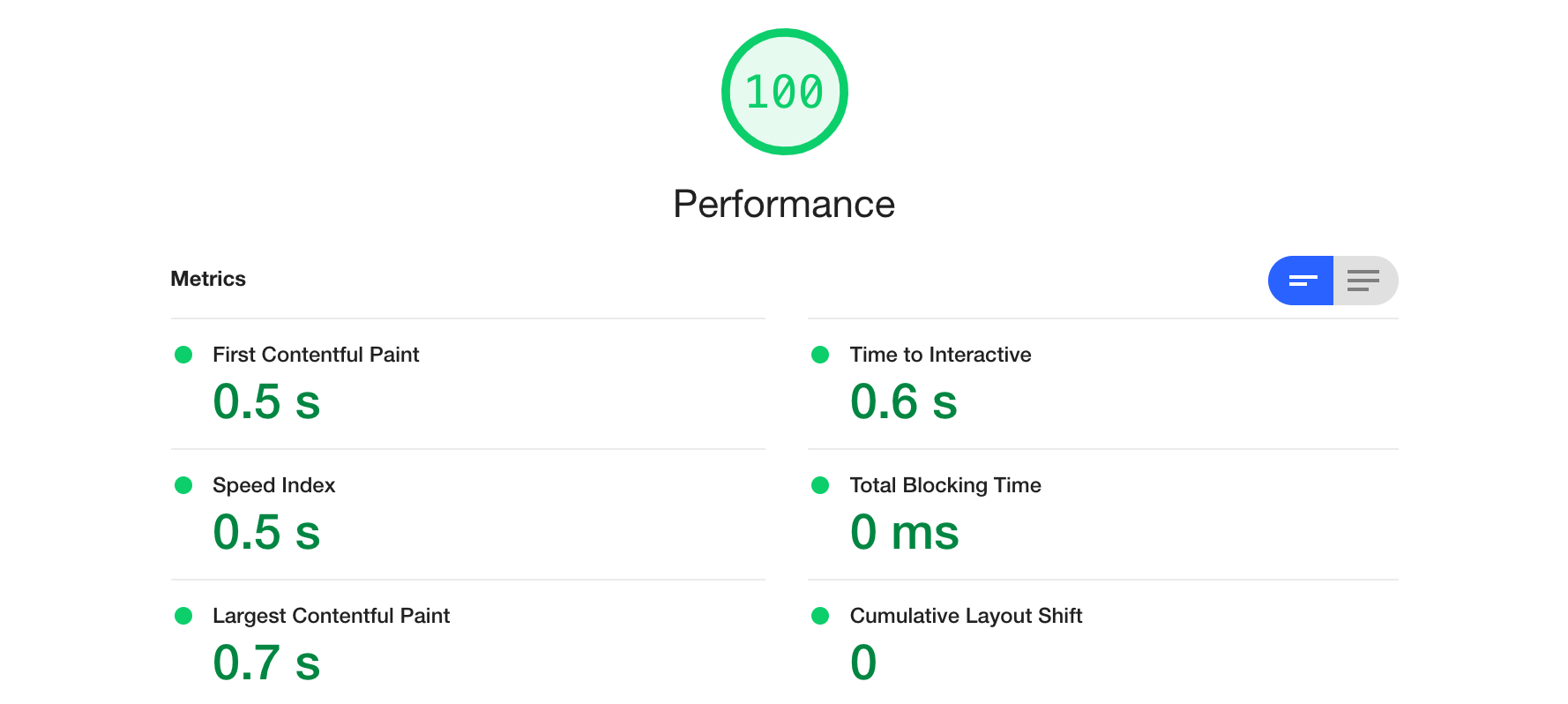
2022年2月9日
雑記2021年6月21日
2021年4月21日
JavaScript2021年4月1日

2021年3月31日
GraphQLTypeScript2021年3月30日
雑記2020年8月3日
Webパフォーマンス2020年5月14日
TypeScript2019年11月8日
2019年10月17日
雑記
久保田光則 (id:anatoo)
福岡在住のソフトウェアエンジニア・UI/UXデザイナー。RelayHub, LLCという会社をやっています。 技術評論社 『HTML5 ハイブリッドアプリ開発[実践]入門』 『Webフロントエンド ハイパフォーマンス チューニング』 好評発売中。
© Mitsunori Kubota